Whenever a website is being popular, BOTs or fraudsters are rushing to it with the purpose to take advantage of the users, the data or the reach the website has. For example posting spam messages in a popular social platform can directly reach a lot of users.
When dealing with these malicious entities, we must perform almost surgical actions in order to keep our users and data safe.
In this article we are going to:
- Go over some definitions
- Define a process to deal with BOTs
- Propose an architecture to implement the process
Definitions
Bot: An Internet bot, web robot, robot or simply bot, is a software application that runs automated tasks over the Internet. Typically, bots perform tasks that are simple and repetitive much faster than a person could. (Wikipedia)
Bot-net: a large number of bots working together to perform their operation in an organized way. They divide and conquer the content they need to crawl
How to deal with Bots
Having the proper process in place is crucial as it will allow you to have control over mitigation or protection levels you want to put in place. There are 4 steps as follows:
- Classification: categorize the type of user a request belong to
- Risk assessment: determine the potential damage this request can do
- Retention: capture relevant information about the request that will help in the previous steps, or be used in analytics or reporting
- Mitigation: depending on the risk factor, determine the action to take, if any
Classification
In general, we classify a request to belong to one of these 3 types of users:
- Real User: a human using a browser or device to navigate through the website
- Good Bot: a good bot is a bot that is helping the website. These are:
- Search Engine bots crawling the website to improve search engine results
- Social Network bots crawling the website to be used as recommendations on their platform
- Aggregator bots used to create custom feeds or increase organic traffic
- Monitoring bots that check the health of the website
- Bad Bot: scripts, tools, motivated users, crowd-sourced traffic or even bot-nets that are looking for malicious outcomes, or abusing the website services to their benefit. They can be:
- Hacker based trying to brute-force or find security holes in order to extract data or abuse a service. Examples go from credit card or PII stealing, email spamming or ransomware. Eventually they can try to perform denial-of-service and request money to cease their activities
- Competitors trying to abuse the ads or leads generated by a website to increase the costs or destabilize the market. They can also shop for the prices and adjust their own website in order to be cheaper by a small amount.
- Cheaters: Some bots are automatically purchasing big deals items (concert tickets, luxury goods) to empty the inventory and then resale on other markets at exorbitant prices.
- Un/Known Bot: a known bot is a previously identified good or bad bot. Marking a bot request as “known bot” can enable different types of strategy. For example a known bad bot will be given a more strict mitigation versus an unknown bad bot. By definition all good bots are known bots. Unknown bots signatures can be cached for faster detection and possibly converted to known bad bot
Now it doesn’t come as a surprise that classifying is the most difficult part of bot management. That is because bots are getting smarter and mimicking real human behaviour. In order to do so, you need to identify what does your website have that can interest someone in sending bots?

Defining bot motivation
We’ve seen some examples above, let’s dig in more details. These are the main types of websites that exist:
- Online shopping
- General goods
- Trips and accommodation
- Movies and concert
- Bill payment
- Newspaper and magazines
- Online gaming
- Finance
- Banking
- Cryptocurrency
- Forex
- Market places
- Buy/sell/rent
- Exchange
- Bidding platform
- Social network and communities
- Messaging
- Blogs
- Forums
- Business or corporate websites
- Service providers
- Hosting
- CI/CD
- Learning platform
- Multimedia
- …
Each of these types of websites give different types of interest to bot owners. I will not go through all of them but just study a few cases.
Online Travel Agent, market places
OTAs and market places are bringing the demand, or buyers, to the offer, or sellers.
Their valuable assets are:
- Content: all the bookable/purchase items come with description, rating, reviews, photos. These are easy one-stop to scrape content for smaller competitors
- Prices: competitors can be interested in the displayed prices of a website and they can set their own prices a bit lower
- Users: more malicious person would try exploiting security aspect of the website in order to steal account information for Account Take Over (ATO), Personal Identifiable Information (PII) collection and reselling or even credit card harvesting
- Spam: it is sometimes possible to exploit a weakness of a website and use its features to send spam emails.
- Denial Of Service (DOS): either simple or distributed (DDOS), a malicious person might want to take down a website to disrupt users and reduce their trust in it
- Ads cost: if there are paid ads on the website, partners that pay per impression or click will be charged for bot traffic. This reduces trust from partners that would see a low return on investment and stop paying to advertise
- Infrastructure cost: similar to the Ads cost, high volume of crawling a website that has auto-scale feature would force keeping a larger number of instances thus increasing the infrastructure cost
Online shopping
Online shopping is similar in a sense to the previous case. But there are additional aspects a bot would exploit:
- Stock starvation: bot can buy all the stocks of highly discounted items, or luxury items (like buying all PS5 on the release date) and resell them at huge mark-up on marketplaces
- Money laundering: buying lots of goods using stolen credit cards then cancelling the orders requesting refund on a different (clean) credit card
Bot tools
Let’s put ourselves in a bot owner’s shoes. If we want to achieve our objective, what are the options in front of us?
- Manual: not the fastest option, but browsing and performing the malicious activity manually is possible. When we multiply the users, we can achieve efficient, hard to detect operations. This is usually for fraud actions where the ROI is high with little efforts
- Replayed traffic: the malicious user can use tools to record all generated traffic for a particular use case, then feed it in a tool that can replay, possibly adjusting some variables to cover more content
- Dynamic script: these are scripts that use an initial url then crawl a page, identify actionable items (hyperlinks, buttons…), auto fill forms and emulate real user activity.
The above last 2 methods, if not done carefully, can have a few flaws that will allow identifying them:
- Use of the same IP address for a large amount of requests
- Not generating real traffic, i.e. not downloading all static content (images, javascript, css, ads…), or in the wrong sequence (submit a lead before opening the page that contains it). Beware of false positive (browser cache, page/tab opened days ago)
- Use of an identifiable user-agent
- Filling input field that shouldn’t be so (honey pot)
- Wrong nonce token (if the website implements such)
Detection
Now that we know what the bots are looking for, we can start putting strategies to detect and identify them. Since we are limited in the information we can collect from a bot, we need to use strategies to generate additional data to be used for identification, or use the collective of data to understand the behaviour of the bot over time.
| Method | Description |
| IP Reputation | Use IP Reputation service like https://talosintelligence.com/reputation_center/ or similar |
| User Agent Validation | User-agent of scripted traffic can have extra spaces, or spaces at the wrong place, invalid character, or well-known bad bot/tools values (i.e. “CURL/1.7.3”). Validate the user-agent with an API or known database. |
| IFrame check | Some automation tools load the target website in IFrame. Checking if the form is submitted from an IFrame can mark a lead as not authorized. Check both client side and server side (send window.top.origin and window.self.origin or similar in the payload) |
| Email validation | Use Email reputation service like https://www.ipqualityscore.com/documentation/email-validation/overview or similar to validate the reputation or validity of the email address. |
| Phone validation | Use Phone number validation API like https://www.ipqualityscore.com/solutions/phone-validation or similar. |
| Device Fingerprinting | Use technique like https://fingerprintjs.com/blog/browser-fingerprinting-techniques/ or similar |
| Cookies/Local Storage | Use cookies/local storage to keep a token representing the leads already sent (keep the token type, i.e. cookies or local storage as prefix to the token). Send it in the lead payload. If server side validation of this token mismatches, reject the lead |
| Hidden field honeypot | Add a fake/hidden field in the form that will be filled only by a script |
| User Behavior Tracing | Keep the last X number of requests and when a lead is submitted, verify the previous requests match a real user behavior. Can be very simple logic (total number of requests to a specific page type, i.e. SERP has 20 results but 50 different detail pages are requested…), or enhanced with Machine Learning. |
Using the above (non-exhaustive) list of checks, we can create a score that will determine the likelihood the request comes from a bot. The flow goes like this:
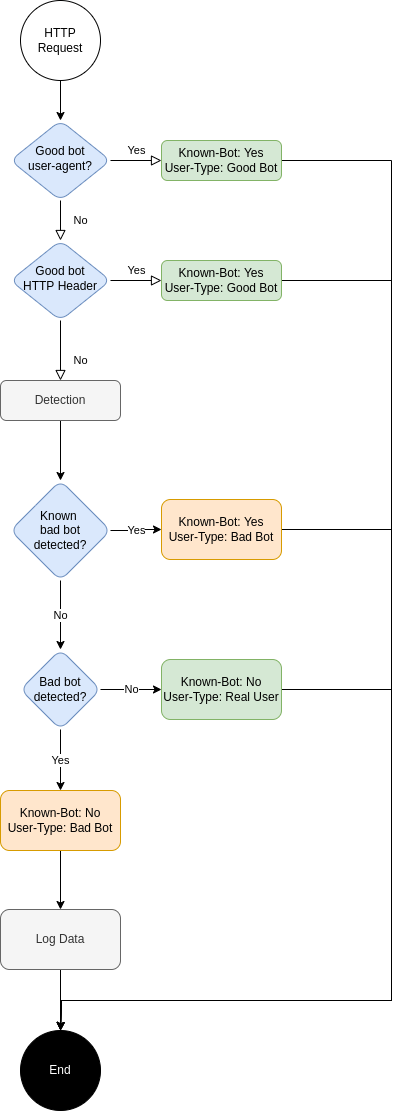
- Check the user-agent or http header for good bot identifying themselves
- If not a good bot, perform the detection.
- Mark the request as known or unknown bad bot if detected
- Otherwise mark the request as real user
- Log the request data, user type and score for future analysis, analytics or loop back for machine learning algorithm tuning
Risk assessment
The risk is usually easy to assess. Depending on the service requested by the bot, we can decide if that poses a threat to anything.
For example a bot making numerous login attempts via brute force attack can be estimated a high risk.
A bad bot crawling the website can be a medium or low risk.
The type of request along with the risk level will help decide how to mitigate the request.
Logging
It is important to log all requests and associated data. It can be used for future analysis, for reporting or even to be looped back in a machine learning algorithm. The data to capture should at least consist of:
- Timestamp
- Request URL
- Request payload (be careful with PII or secrets, credentials or credit card details)
- IP address
- User-agent
- User Type
- Detection score
Mitigation
The action taken when we deal with a bot request is called a mitigation. There are several ways to mitigate a bot request. Sometimes the mitigation is to let the bot continue if there is no risk of damage. The common mistake is to block bots. The problem with this approach is the bot can understand it has been detected and adapt to be harder to detect.
Obviously, if a critical business impact is occurring, blocking the bot is a perfectly fine option to temporarily prevent user or business damages.
Static response or cached data
A first option is to ignore the request, and directly send a successful response to the bot to make it think it is succeeding in its actions. Alternatively returning cached, possibly obsolete data.
Throttling
If possible, i.e. the cost of doing so isn’t greater than the damage from the bot, throttle the requests from the bot to slow them down. Depending on what it is aiming for, throttling might discourage the bot to continue.
Dedicated server
Another option is to route the request to a different web server that would serve cached data. This way the server capacity is dedicated to real users.
Proposed architectures
Now that we know how to identify bot and how to mitigate their actions, the next step is to build a system that will help us automate this all.
Putting it all together
There are several ways this can be handled, but I wanted to share 2 types of approaches. One is good for a small architecture where there is typically a single web-application. The other one is for more distributed applications that need to benefit of the same detection. You can then evolve them at your needs.
Middleware to do it all
Most frameworks provide a middleware layer where the whole process can be implemented. Although it is quick and easy to do, there are several limitations:
- Code can become complex to maintain or to increase the features
- High volume of request will still affect the capacity of the server, reducing the effectiveness
- The logic needs to be implemented in every websites which could be in different languages
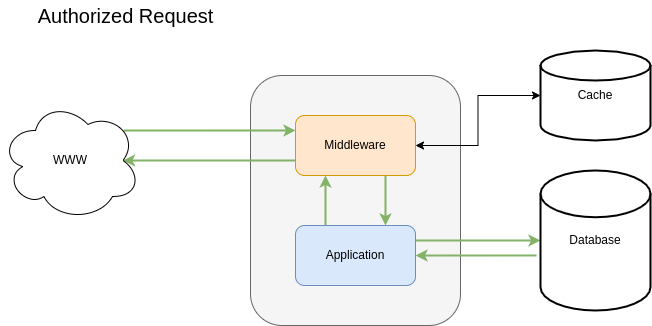
In the case the HTTP request is from a real user, proceed as normal. In this case the middleware has all the logic to detect, classify and mitigate. Application level can also mitigate for finer mitigation:
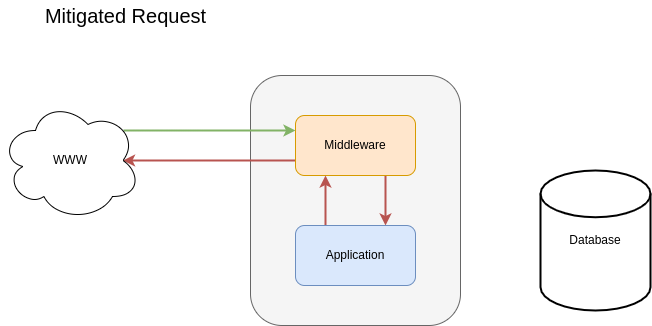
In the case of a bad bot, mitigate with the appropriate response from the application layer.
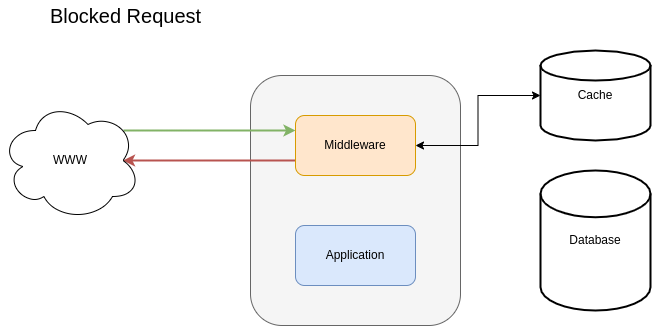
However, in the case of a very bad bot, you can have logic in the middleware to block the request immediately.
Dedicated Service
A decentralised approach would work better for larger organisations or when there are multiple systems that need similar protection.
The advantages are:
- Easier to scale the infrastructure
- Decoupled from other systems
- Easier to on-board new systems
Here is the proposed design:
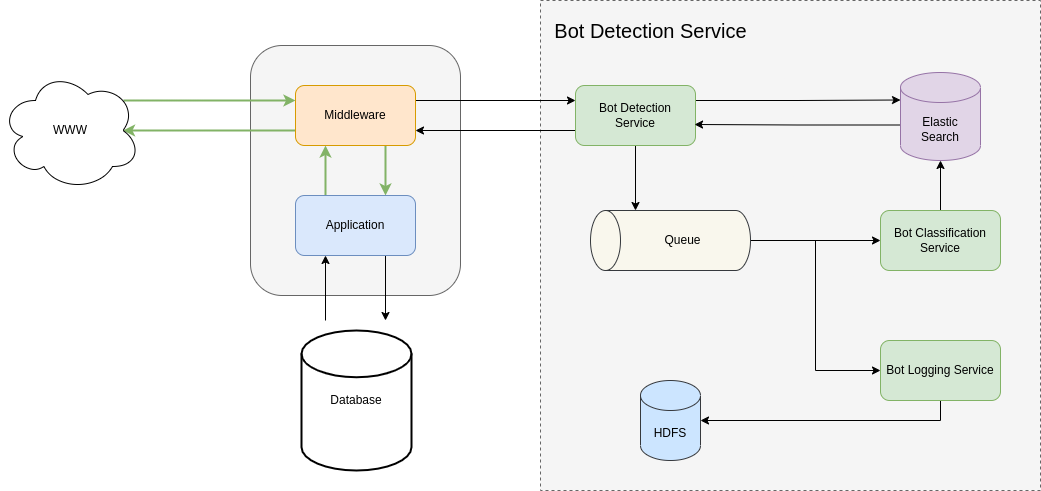
- A request comes in the web-application
- The Bot Detection middleware creates a request to the Bot Detection Service
- The Bot Detection Service does 3 things:
- Build the user signature (see below)
- Push the request with its user signature to a queue for further analysis
- Search the signature in Elastic Search and return the result to the caller of the API
- The middleware attaches the bot service response to the request (can be injected as HTTP Header or Cookies for easier access from the lower layer of the application)
- The Bot Classification Service analyses the request and inserts or updates Elastic Search if there is detection of good or bad bot (known or unknown), using the user signature
- The Bot Logging Service also consumes messages from the queue and stores it to a data warehouse
In the application layer, most likely at the Controller level if you are using an MVC framework, you can access the bot data from the added HTTP Header or Cookies and make decision on:
- The risk
- The mitigation
In this architecture, you can add more services (detection, classification and even logging) to handle the volume of the requests.
User Signature
The user signature can help quickly find a previously identified user or bot. The information used for this signature should not be specific to the request. For example the user signature could be the hash of a JSON data composed of:
- The IP Address
- The User-Agent
- The device fingerprint (if any)
Conclusion
Bots can be hard to detect. If you have the right system in place to detect and mitigate their actions, and you can enhance the methods of detection at scale, then you are in a much better position. In another post, I will drill down on the detection methods that can be implemented.